


本文档总结了在 Arch Linux 系统上,从零开始搭建环境并成功部署 vLLM 推理服务的全过程。
一、 环境准备 (Level 2 前置任务)
在正式开始项目前,我们在 Arch Linux 主机上完成了所有必要的环境配置。
1. NVIDIA 驱动安全安装
为了确保稳定性和性能,我们采用了一套稳妥的方案来安装 NVIDIA 驱动。
- 安装方式: 使用
nvidia-dkms包,确保驱动在内核更新后能自动重新编译。 - 关键配置:
- Early KMS: 修改
/etc/mkinitcpio.conf文件,在MODULES数组中添加nvidia nvidia_modeset nvidia_uvm nvidia_drm,以防止启动时黑屏。 - 内核参数: 修改
/etc/default/grub,在GRUB_CMDLINE_LINUX_DEFAULT中添加nvidia_drm.modeset=1,以优化兼容性。
- Early KMS: 修改
- 成果: 驱动安装成功,
nvidia-smi命令可正确显示 RTX 4060 显卡信息。
2. Docker 环境搭建
-
安装 Docker: 使用
sudo pacman -Syu docker安装 Docker 引擎。 -
配置服务: 使用
systemctl start docker和systemctl enable docker启动并设置开机自启。 -
用户组配置: 通过
sudo usermod -aG docker $USER将当前用户添加到docker组,实现了免sudo执行 docker 命令。
ps:docker会被墙,需要使用国内源,这里推荐一个github项目DockerHub,这里面提供了最新的可用的国内镜像源。
3. NVIDIA Container Toolkit 安装
-
安装: 使用
sudo pacman -S nvidia-container-toolkit在 Arch Linux 上安装。 -
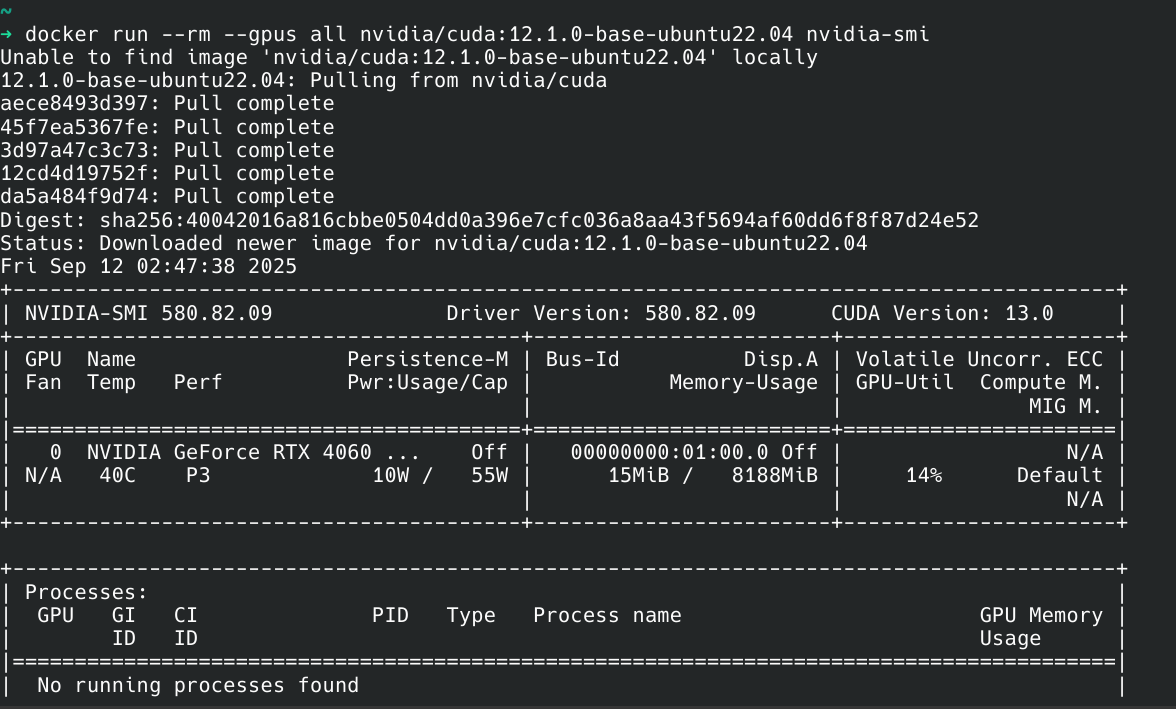
验证: 成功运行了测试容器,证明 Docker 可以正确调用 GPU。
Bash
docker run --rm --gpus all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi该命令在容器内部成功打印出了
nvidia-smi的信息,确认了主机驱动、Docker 和 Toolkit 之间的桥梁已搭建成功。
二、 Level 1: 运行第一个 Web 服务
此阶段的目标是掌握 Docker 的基本工作流程。
1. app.py (Python Flask 应用)
一个简单的 Python Flask 应用。
from flask import Flask, jsonify
import platform
app = Flask(__name__)
@app.route('/')
def hello():
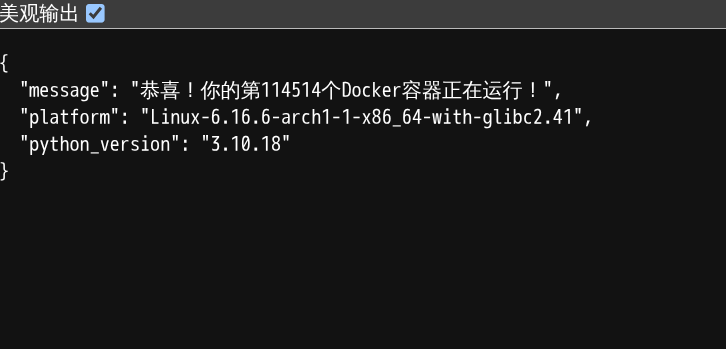
return jsonify({
"message": "恭喜!你的第114514个Docker容器正在运行!",
"platform": platform.platform(),
"python_version": platform.python_version()
})
@app.route('/health')
def health():
return jsonify({"status": "healthy"})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)2. requirements.txt (Python 依赖文件)
包含 Flask 依赖。
Flask3. Dockerfile (容器构建指令)
定义了如何构建 Python 应用镜像的指令集。
# 基础镜像 - 就像选择操作系统
FROM python:3.10-slim
# 设置工作目录 - 就像进入特定文件夹
WORKDIR /app
# 复制依赖文件
COPY requirements.txt .
# 安装依赖 - 就像安装软件
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY app.py .
# 暴露端口 - 告诉Docker哪个端口会被使用
EXPOSE 5000
# 启动命令 - 容器启动时执行
CMD ["python", "app.py"]-
核心命令:
Bash
# 1. 构建镜像 (我们将镜像命名为 first) docker build -t first . # 2. 运行容器 (将主机的5000端口映射到容器的5000端口) docker run --rm -p 5000:5000 first -
成果: 成功通过浏览器访问
http://localhost:5000,并看到了应用返回的 JSON 祝贺信息。
Level 2: 搭建 GPU 加速的 Docker 环境
目标
此阶段的核心目标是让 Docker 容器能够调用你主机(Arch Linux)的 NVIDIA GPU 强大算力。这是所有后续 AI 应用容器化部署的绝对基础。
可以把它想象成给你的 Docker“集装箱”安装一个特殊的接口,让它能够连接到电脑的“涡轮增压引擎”(GPU)。
第一步:安装核心组件 - NVIDIA Container Toolkit
要实现 Docker 和 GPU 之间的通信,我们需要 NVIDIA 官方提供的一个关键工具:NVIDIA Container Toolkit。
-
在 Arch Linux 上安装 Toolkit 这个工具包已经被收录在 Arch 的官方仓库中,安装非常简单。
sudo pacman -S nvidia-container-toolkit -
重启 Docker 服务 安装完成后,必须重启 Docker 服务,这样 Docker 才能识别到新安装的 Toolkit 并加载它的配置。
sudo systemctl restart docker
第二步:基础验证 - 在容器内运行 nvidia-smi
这是最直接、最快速的验证方法,用来确认 Toolkit 是否安装成功。我们将启动一个包含 CUDA 环境的官方容器,并在容器内部尝试运行 nvidia-smi 命令。
-
运行测试容器
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi命令解释:
--rm: 容器运行结束后自动删除,保持系统干净。--gpus all: 这是最关键的参数,它告诉 Docker 把主机上所有可用的 NVIDIA GPU 都授权给这个容器使用。
-
预期成果 如果一切配置正确,你会在终端看到和你在自己电脑上直接运行
nvidia-smi时一模一样的显卡信息表格。这证明 Docker 已经成功地“看”到了你的 GPU。
第三步:进阶验证 - 在容器内用 PyTorch 检测 GPU
nvidia-smi 只能证明底层驱动是通的。为了确保 AI 框架也能正常使用 GPU,我们可以创建一个包含 PyTorch 的环境来做一次最终测试。
-
创建 Python 测试脚本 (
gpu_test.py) 在你的项目根目录~/hunyuan-project下,创建一个名为gpu_test.py的文件。cd ~/hunyuan-project nano gpu_test.py将以下代码粘贴进去:
import torch print("--- PyTorch CUDA 检测 ---") if torch.cuda.is_available(): print("✅ 太棒了!PyTorch 成功检测到 CUDA!") print(f"CUDA 设备数量: {torch.cuda.device_count()}") gpu_index = 0 print(f"当前 GPU 索引: {gpu_index}") print(f"当前 GPU 名称: {torch.cuda.get_device_name(gpu_index)}") total_mem = torch.cuda.get_device_properties(gpu_index).total_memory / 1e9 print(f"显存总量: {total_mem:.2f} GB") else: print("❌ 糟糕... PyTorch 未能检测到 CUDA 设备。") print("-------------------------") -
为 PyTorch 测试创建专用 Dockerfile 为了避免污染我们之前的
vllm-service镜像,我们创建一个新的 Dockerfile,专门用于这个测试。我们把它命名为Dockerfile.gpu-test。nano Dockerfile.gpu-test将以下内容粘贴进去:
# 直接使用 PyTorch 官方提供的、内置 CUDA 和 CUDNN 的镜像,这是最方便可靠的方式 FROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-runtime # 设置工作目录 WORKDIR /app # 将我们的测试脚本复制进去 COPY gpu_test.py . # 设置容器启动时要执行的命令 CMD ["python", "gpu_test.py"] -
构建并运行 PyTorch 测试镜像
# 使用 -f 参数指定我们刚刚创建的 Dockerfile 文件名来构建镜像 docker build -t gpu-test-app -f Dockerfile.gpu-test . # 运行这个测试容器,同样需要 --gpus all 参数 docker run --rm --gpus all gpu-test-app -
预期成果 运行成功后,你会在终端看到类似下面的输出:
--- PyTorch CUDA 检测 --- ✅ 太棒了!PyTorch 成功检测到 CUDA! CUDA 设备数量: 1 当前 GPU 索引: 0 当前 GPU 名称: NVIDIA GeForce RTX 4060 Laptop GPU 显存总量: 7.99 GB -------------------------
三、 Level 3: 部署 vLLM 推理服务
此阶段是项目的核心,目标是构建并运行一个功能强大的 vLLM 服务容器。这个过程遇到了多次依赖和环境不兼容问题,最终通过一个稳健的 Dockerfile 方案得以解决。
Dockerfile
# 使用一个非常新的 CUDA 12.4.1 基础镜像,以获得最好的兼容性
FROM nvidia/cuda:12.4.1-base-ubuntu22.04
# 设置环境变量,避免 apt-get 在构建时弹出交互窗口
ENV DEBIAN_FRONTEND=noninteractive
# 直接下载并从源码编译安装 Python 3.12,以绕过 PPA 网络问题
RUN apt-get update && \
apt-get install -y wget build-essential libssl-dev zlib1g-dev libncurses5-dev \
libncursesw5-dev libreadline-dev libsqlite3-dev libgdbm-dev libdb5.3-dev \
libbz2-dev libexpat1-dev liblzma-dev tk-dev libffi-dev git && \
wget https://www.python.org/ftp/python/3.12.4/Python-3.12.4.tgz && \
tar -xf Python-3.12.4.tgz && \
cd Python-3.12.4 && \
./configure --enable-optimizations && \
make -j $(nproc) && \
make altinstall && \
cd .. && \
rm -rf Python-3.12.4.tgz Python-3.12.4 && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# 为 python3 和 pip3 创建软链接,指向我们新安装的 3.12 版本
RUN ln -s /usr/local/bin/python3.12 /usr/local/bin/python3 && \
ln -s /usr/local/bin/pip3.12 /usr/local/bin/pip3
# 安装一组已知兼容的最新核心库
RUN pip3 install \
"torch==2.4.0" \
"vllm==0.5.3.post1" \
"transformers==4.42.4" \
"outlines==0.0.34"
# 设置工作目录和模型缓存目录
WORKDIR /app
RUN mkdir -p /models
ENV TRANSFORMERS_CACHE=/models
EXPOSE 8000
# 启动 vLLM 服务,使用小的测试模型
CMD ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "facebook/opt-125m", \
"--host", "0.0.0.0", \
"--port", "8000"]核心命令与成果
-
构建与运行:
Bash
# 构建 vLLM 服务镜像 docker build -t vllm-service . # 在后台以 GPU 模式启动容器,并挂载模型存储卷 docker run --gpus all \ -p 8000:8000 \ -v $(pwd)/models:/models \ --name vllm-server \ -d \ vllm-service -
验证:
- 通过
docker logs vllm-server确认服务成功启动。 - 编写并运行
test_api.py脚本,成功向http://localhost:8000发送请求并收到了由facebook/opt-125m模型生成的文本。
- 通过
项目实践记录:Level 4 - 大模型部署总结
1. 核心思路
由于本蒟蒻的 RTX 4060 显卡有 8GB 显存,所以选择了一个很小、适合个人电脑部署的 Qwen2-0.5B-Instruct 模型。
- 模型选择:Qwen2-0.5B-Instruct 是一个参数量仅为 5 亿的模型,它对硬件资源的需求极低,能够稳定、快速地在设备上运行。
- 部署工具:继续使用 Docker 和 vLLM。通过精简的启动命令,我们避免了复杂的显存参数调试,让部署过程变得更加简单和可靠。
2. 部署详细步骤
这是一个从零开始部署这个新模型的完整指南。
第1步:下载 Qwen2 0.5B 模型
首先,停止你当前正在运行的 Docker 容器,然后下载新的模型。这个过程比之前快得多,也更稳定。
Bash
# 克隆 Qwen2 0.5B 模型
git clone https://huggingface.co/Qwen/Qwen2-0.5B-Instruct第2步:启动 vLLM 服务
新模型的启动命令非常简洁。你不再需要 --quantization、--max-model-len 或 --gpu-memory-utilization 等复杂参数。
Bash
docker run --gpus all --rm \
-p 8000:8000 \
-v $(pwd)/Qwen2-0.5B-Instruct:/models \
--name vllm-server \
vllm/vllm-openai \
--model /models \
--served-model-name qwen2-0.5b-instruct第3步:验证服务与模型
服务启动后,打开一个新的终端,使用 curl 命令验证 API 接口。
-
验证服务就绪:
Bash
curl http://localhost:8000/v1/models你应该会看到一个 JSON 响应,其中包含模型 ID
qwen2-0.5b-instruct。 -
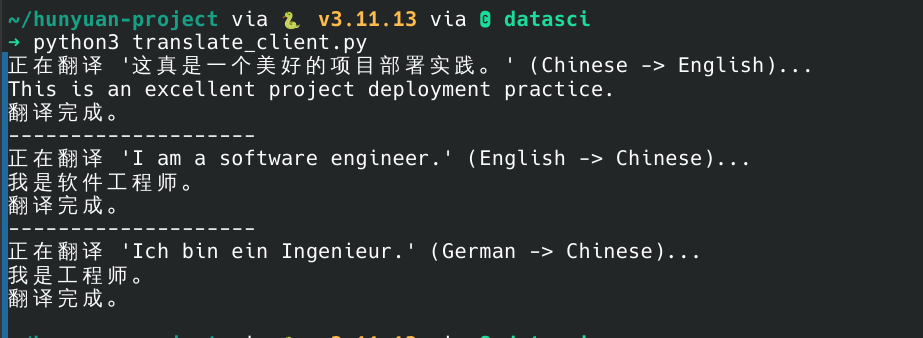
测试翻译功能:
使用对话格式向模型发送一个翻译请求。
Bash
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "qwen2-0.5b-instruct", "messages": [ { "role": "system", "content": "You are a professional translator. Translate all user text into English." }, { "role": "user", "content": "你好,世界" } ], "max_tokens": 50 }'如果一切正常,模型将返回正确的翻译结果,证明你已经成功部署了服务。
项目进阶教程 (Level 5-7)
我们已经成功部署了 vLLM 后端服务。接下来的目标是将这个强大的 AI 能力,封装成一个用户可以直观交互的全功能 Web 应用。
准备工作:最终的项目结构
为了让项目清晰有序,我们先规划好最终的目录结构。请在你的 hunyuan-project 根目录下,组织或创建如下结构:
hunyuan-project/
├── backend/
│ ├── app.py # 我们的 Flask 后端(API 网关 + 前端服务)
│ └── Dockerfile # 用于构建 Flask 后端的 Dockerfile
├── frontend/
│ └── index.html # 用户看到的网页前端
├── models/
│ └── ... # 你下载的模型文件
└── docker-compose.yml # 编排所有服务的“总指挥”(请注意,我们将把 Flask 后端的代码放在 backend 目录,前端页面放在 frontend 目录)
Level 5 & 6: 构建前后端应用
在这个阶段,我们将同时完成 Level 5 (创建后端) 和 Level 6 (创建前端),因为它们是紧密协作的。
第一部分:创建后端服务 (backend/app.py)
我们的后端是一个 Python Flask 应用。它有两个核心职责:
- 作为一个 API 网关,接收前端的翻译请求,转发给 vLLM 服务,并把结果流式返回。
- 作为一个 Web 服务器,向用户的浏览器提供前端的
index.html页面。
1. 创建 backend/app.py 文件
Bash
# 确保在项目根目录
cd ~/hunyuan-project
# 创建 backend 目录
mkdir -p backend
# 创建并编辑 app.py
nano backend/app.py2. 编写 app.py 完整代码
请将以下完整代码复制到 app.py 文件中。代码的详细解释在注释里。
Python
# 导入所有需要的库
from flask import Flask, request, jsonify, Response, send_from_directory
from flask_cors import CORS # 用于处理跨域请求
import requests # 用于向 vLLM 服务发送 HTTP 请求
import json
import os
# 初始化 Flask 应用
# static_folder='../frontend' 告诉 Flask 去上一级的 'frontend' 目录寻找静态文件 (index.html)
app = Flask(__name__, static_folder='../frontend')
CORS(app) # 启用CORS,允许前端页面访问此后端
# --- vLLM 服务配置 ---
# vLLM 服务的地址。'vllm-backend' 是我们在 docker-compose.yml 中定义的服务名。
# 因为在同一个 Docker 网络中,服务之间可以通过名字直接通信。
VLLM_API_URL = "http://vllm-backend:8000/v1/chat/completions"
# 我们将要提供服务的模型名称
MODEL_NAME = "qwen2-0.5b-instruct"
# --- 路由定义 ---
# 根路径路由 ('/'):当用户访问网站根目录时,返回前端的 index.html 文件
@app.route('/')
def serve_frontend():
return send_from_directory(app.static_folder, 'index.html')
# 翻译 API 路由 ('/translate'):处理前端发来的翻译请求
@app.route('/translate', methods=['POST'])
def translate():
try:
# 1. 从前端请求中获取 JSON 数据
data = request.json
user_text = data.get('text')
source_lang = data.get('source_lang', 'Chinese')
target_lang = data.get('target_lang', 'English')
if not user_text:
return jsonify({"detail": "No text provided"}), 400
# 2. 构建发送给 vLLM 的请求体 (payload),遵循 OpenAI API 格式
vllm_payload = {
"model": MODEL_NAME,
"messages": [
{
"role": "system",
"content": "You are a helpful translation assistant."
},
{
"role": "user",
"content": f"Translate the following text from {source_lang} to {target_lang}. Provide only the translated text, without any additional explanations.\n\nText to translate: {user_text}"
}
],
"max_tokens": 150,
"stream": True # 开启流式传输,这是实现打字机效果的关键
}
# 3. 向 vLLM 服务发送请求,并设置为流式接收
vllm_response = requests.post(VLLM_API_URL, json=vllm_payload, stream=True)
vllm_response.raise_for_status() # 如果 vLLM 返回错误,这里会抛出异常
# 4. 定义一个生成器函数,逐块处理并返回流式数据
def generate():
for chunk in vllm_response.iter_lines(decode_unicode=True):
if chunk:
# 按照 Server-Sent Events (SSE) 格式返回给前端
yield f"{chunk}\n\n"
# 5. 将生成器作为流式响应返回给前端
return Response(generate(), mimetype='text/event-stream')
except requests.exceptions.RequestException as e:
return jsonify({"detail": f"连接 vLLM 服务失败: {e}"}), 500
except Exception as e:
return jsonify({"detail": f"发生意外错误: {e}"}), 500
# 应用启动入口
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)第二部分:创建前端界面 (frontend/index.html)
这个文件是用户在浏览器中直接看到的界面。它包含了页面的结构 (HTML)、样式 (CSS) 和交互逻辑 (JavaScript)。
1. 创建 frontend/index.html 文件
Bash
# 确保在项目根目录
cd ~/hunyuan-project
# 创建 frontend 目录
mkdir -p frontend
# 创建并编辑 index.html
nano frontend/index.html2. 编写 index.html 完整代码
请将以下完整代码复制到 index.html 文件中。
HTML
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI 翻译应用</title>
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Noto+Sans+SC:wght@400;700&display=swap" rel="stylesheet">
<style>
/* CSS 样式部分:负责页面的美化 */
:root {
--primary-color: #007bff;
--primary-hover-color: #0056b3;
--background-start: #e0f7fa;
--background-end: #b2ebf2;
--card-background: rgba(255, 255, 255, 0.7);
--text-color: #34495e;
--border-color: rgba(0, 0, 0, 0.1);
--shadow-color: rgba(0, 0, 0, 0.1);
}
body {
font-family: 'Noto Sans SC', sans-serif;
margin: 0;
padding: 40px 20px;
background: linear-gradient(135deg, var(--background-start), var(--background-end));
color: var(--text-color);
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
box-sizing: border-box;
}
.container {
width: 100%;
max-width: 700px;
padding: 30px;
background: var(--card-background);
backdrop-filter: blur(10px);
box-shadow: 0 8px 32px 0 var(--shadow-color);
border-radius: 15px;
border: 1px solid rgba(255, 255, 255, 0.18);
}
h1 { text-align: center; font-weight: 700; margin-bottom: 30px; }
.language-selector { display: flex; justify-content: space-between; align-items: center; margin-bottom: 20px; gap: 10px; }
.language-selector select { flex-grow: 1; padding: 12px; border-radius: 8px; border: 1px solid var(--border-color); font-size: 16px; }
#swapButton { padding: 10px; border: 1px solid var(--border-color); border-radius: 50%; cursor: pointer; width: 44px; height: 44px; display: flex; justify-content: center; align-items: center; transition: transform 0.3s ease; }
#swapButton:hover { transform: rotate(180deg); }
textarea { width: 100%; box-sizing: border-box; padding: 15px; border-radius: 8px; border: 1px solid var(--border-color); font-size: 16px; min-height: 150px; resize: vertical; margin-bottom: 20px; }
textarea:focus { outline: none; border-color: var(--primary-color); }
button { width: 100%; padding: 15px; font-size: 18px; font-weight: 700; color: white; background: var(--primary-color); border: none; border-radius: 8px; cursor: pointer; transition: background-color 0.3s ease; }
button:hover { background: var(--primary-hover-color); }
button:disabled { background-color: #95a5a6; cursor: not-allowed; }
.result-box { min-height: 150px; padding: 15px; background-color: rgba(255, 255, 255, 0.5); border-radius: 8px; border: 1px solid var(--border-color); margin-top: 20px; white-space: pre-wrap; word-wrap: break-word; font-size: 16px; }
</style>
</head>
<body>
<div class="container">
<h1>AI 翻译应用</h1>
<div class="language-selector">
<select id="sourceLang">
<option value="Chinese">中文 (Chinese)</option>
<option value="English">英文 (English)</option>
<option value="German">德语 (German)</option>
<option value="Japanese">日语 (Japanese)</option>
<option value="French">法语 (French)</option>
</select>
<button id="swapButton" title="交换语言">
<svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><line x1="12" y1="5" x2="12" y2="19"></line>
<polyline points="19 12 12 19 5 12"></polyline></svg>
</button>
<select id="targetLang">
<option value="English">英文 (English)</option>
<option value="Chinese">中文 (Chinese)</option>
<option value="German">德语 (German)</option>
<option value="Japanese">日语 (Japanese)</option>
<option value="French">法语 (French)</option>
</select>
</div>
<textarea id="inputText" rows="6" placeholder="在此输入要翻译的文本..."></textarea>
<button id="translateButton">翻译</button>
<div class="result-box" id="resultText">翻译结果将显示在这里。</div>
</div>
<script>
// 1. 获取所有需要操作的 HTML 元素
const sourceLangSelect = document.getElementById('sourceLang');
const targetLangSelect = document.getElementById('targetLang');
const swapButton = document.getElementById('swapButton');
const translateButton = document.getElementById('translateButton');
const inputTextElement = document.getElementById('inputText');
const resultTextElement = document.getElementById('resultText');
// 2. 实现“交换语言”功能
swapButton.addEventListener('click', () => {
const temp = sourceLangSelect.value;
sourceLangSelect.value = targetLangSelect.value;
targetLangSelect.value = temp;
});
// 3. 实现核心的“翻译”功能
translateButton.addEventListener('click', async () => {
const inputText = inputTextElement.value;
if (!inputText.trim()) {
resultTextElement.innerText = "请输入要翻译的文本。";
return;
}
// 提供即时反馈:禁用按钮并更新文本
resultTextElement.innerText = "";
translateButton.disabled = true;
translateButton.innerText = "翻译中...";
try {
// 使用 fetch API 向我们的 Flask 后端发送请求
const response = await fetch('/translate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
text: inputText,
source_lang: sourceLangSelect.value,
target_lang: targetLangSelect.value
})
});
if (!response.ok) {
const error = await response.json();
throw new Error(error.detail || '未知服务器错误');
}
// 处理流式响应
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split('\n');
// 解析 SSE 数据块
for (const line of lines) {
if (line.startsWith('data: ')) {
const jsonData = line.substring(6);
if (jsonData === '[DONE]') break;
try {
const parsed = JSON.parse(jsonData);
const content = parsed.choices[0].delta.content;
if (content) {
// 将内容实时追加到结果区,实现打字机效果
resultTextElement.innerText += content;
}
} catch (e) {
// 忽略偶尔的解析错误
}
}
}
}
} catch (error) {
resultTextElement.innerText = `请求失败: ${error}`;
} finally {
// 无论成功或失败,最后都恢复按钮状态
translateButton.disabled = false;
translateButton.innerText = "翻译";
}
});
</script>
</body>
</html>Level 7: 使用 Docker Compose 编排
现在我们有了两个服务(vLLM 和我们的前后端应用),我们需要一个工具来同时管理它们。这就是 docker-compose 的作用。
- 创建 docker-compose.yml 文件
在你项目的根目录 ~/hunyuan-project 下创建这个文件。
2. 编写 docker-compose.yml 完整代码
请将以下完整代码复制到 docker-compose.yml 文件中。
YAML
services:
# 服务一:vLLM 模型后端
vllm-backend:
container_name: vllm-server
# 使用 vLLM 官方提供的、内置 OpenAI 兼容接口的镜像
image: vllm/vllm-openai:latest
ports:
- "8000:8000"
volumes:
# 将我们本地的 Qwen2 模型文件夹,挂载到容器内部的 /models 目录
- ./models/Qwen2-0.5B-Instruct:/models
# 覆盖镜像的默认启动命令,让它加载我们指定的模型
command:
- "--model"
- "/models"
- "--served-model-name"
- "qwen2-0.5b-instruct"
- "--host"
- "0.0.0.0"
# 这是在 Docker Compose v2 中为容器分配 GPU 资源的推荐方式
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- custom-network
# 服务二:我们的 Flask 前后端应用
frontend:
container_name: web-frontend
# build 指令告诉 Docker Compose 如何构建这个服务的镜像
build:
context: ./backend # 使用 'backend' 目录作为构建上下文
dockerfile: Dockerfile # 指定该目录下的 Dockerfile
ports:
- "5000:5000"
# depends_on 确保 vllm-backend 服务先启动,再启动本服务
depends_on:
- vllm-backend
networks:
- custom-network
# 定义一个自定义桥接网络,让两个服务可以互相通信
networks:
custom-network:
driver: bridge3. 一键启动整个应用
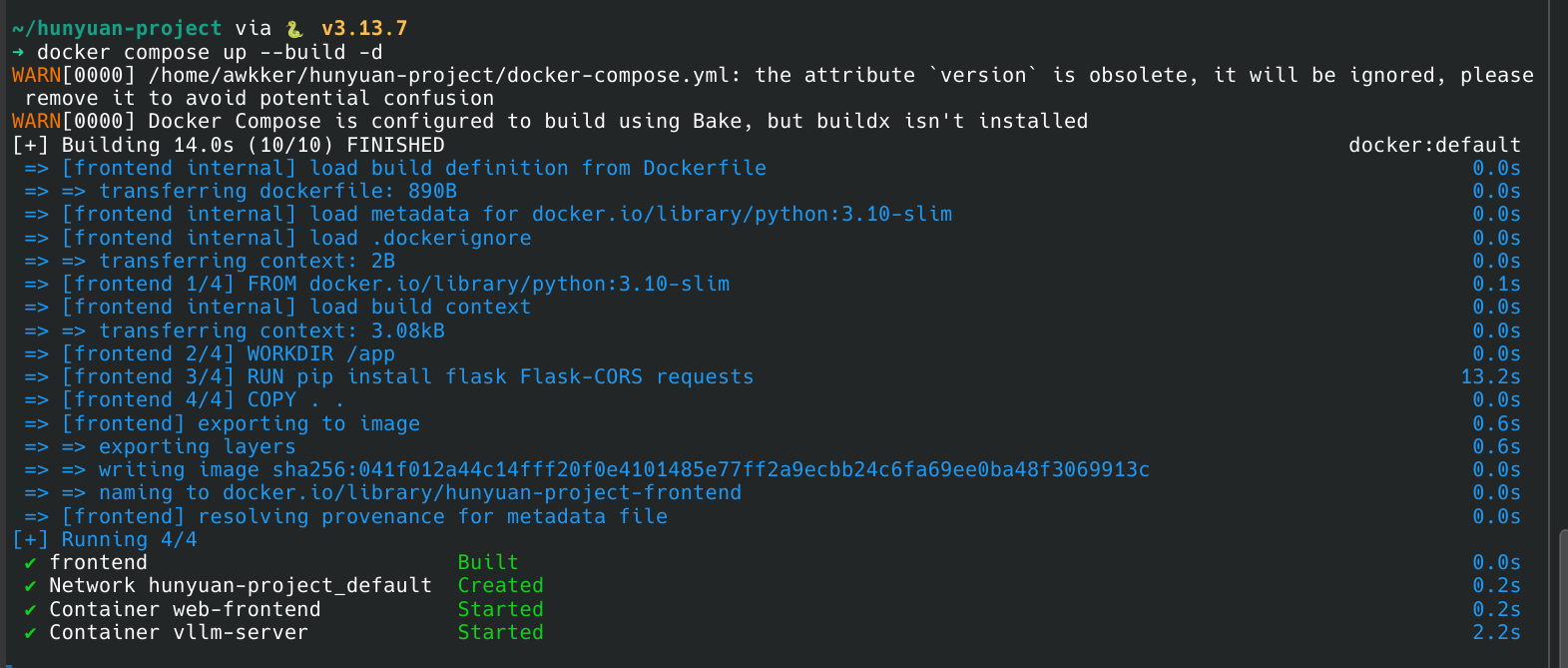
现在,在 hunyuan-project 根目录下,运行最终的命令:
Bash
docker-compose up --build等待所有服务启动成功后,打开浏览器,访问 http://localhost:5000,你就能看到并使用你亲手打造的全栈 AI 翻译应用了!
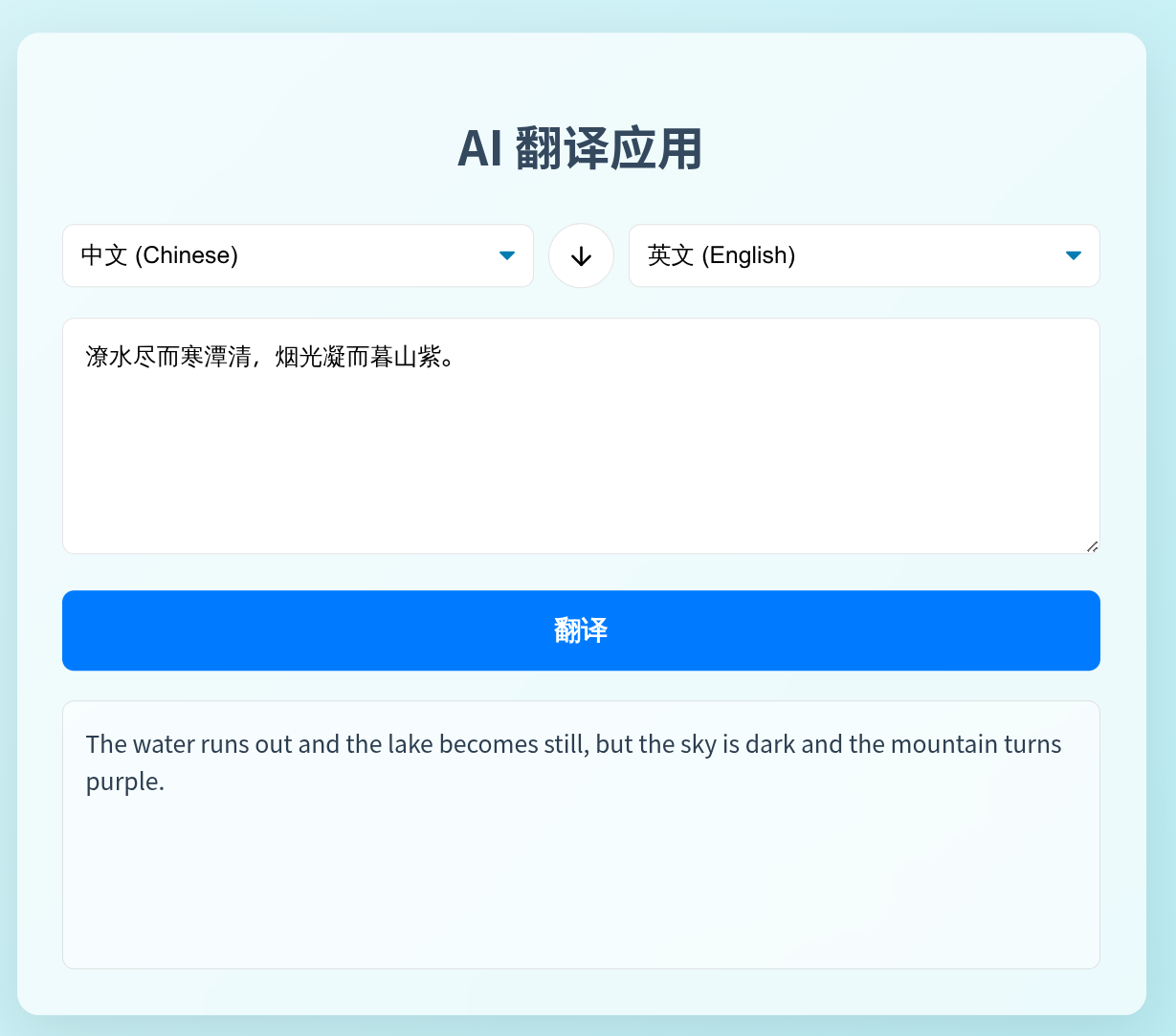
恭喜🎉你完成了全部内容🎉
Comments NOTHING